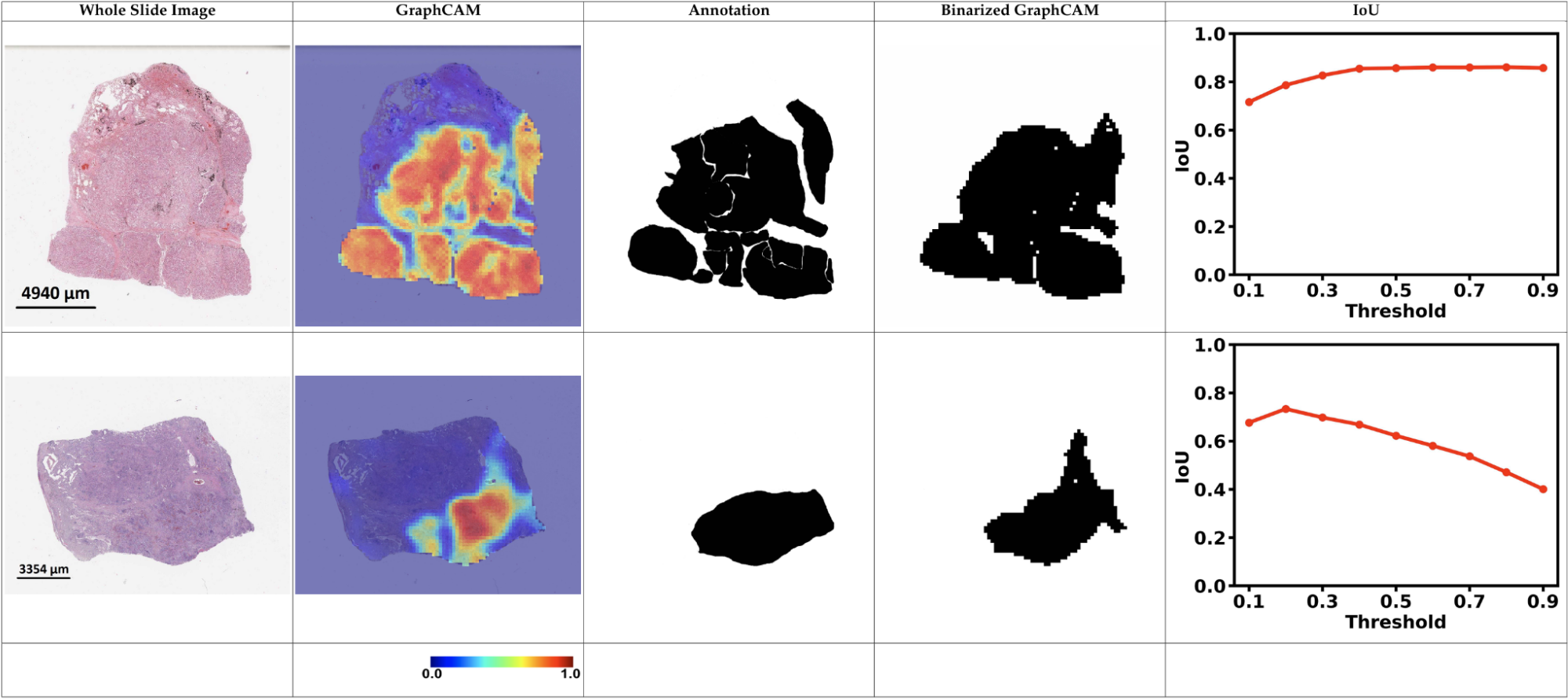
Graph-Transformer Pathology (GTP) Network
Traditional visual deep learning architectures—such as convolutional neural networks (CNNs), Vision Transformers, and MLP-Mixers—are not well-suited for processing gigapixel images, as the image dimensions often exceed 10,000 pixels per side. Directly downsampling such high-resolution images to standard input sizes (e.g., 256×256) results in substantial loss of critical visual information. To address this limitation, we represent gigapixel images as graphs, where image patches serve as nodes and are connected based on k-nearest neighbors in the spatial (x, y) domain. We then employ a graph-based transformer model to learn context-aware node embeddings that capture both local and global structural information. These embeddings offer a compact yet expressive representation of the original gigapixel image and can be readily applied to a range of downstream tasks such as classification, regression, and image captioning. Addtionally, we present a novel Graph-based Class Activation Mapping (GraphCAM) method to generate image-level saliency maps that can identify image regions that are highly associated with the output: